
ASCIIやUnicodeやUTF-16や、なんだか色々あるのは知ってますが、具体的に何がどういう関係になっているのかについて、ちゃんとは理解していないので、自分なりにまとめたいと思います。
ただし、ちょっとモヤモヤが残る・・。
ビットって苦手なんですよね・・
文字コードとは
文字1つ1つに割り当てられている番号(符号:コードポイント)のことをいいます。
この番号から、0と1のビットに変換され、晴れてコンピュータはその中身を理解することができます。
この文字コードは、世界で一意の値というわけではなく、どの対応表(CCS)で定義されるかで決まってきます。そしてその文字コードは、それぞれ決まった形式(CES)でビットに変換されます。
符号化文字集合と文字符号化方式とは?
CCS, CESには様々な種類がありますので、それぞれ一つずつ説明したいと思います。
符号化文字集合(CCS)
文字とコードポイントの対応表(Coded Character Set)のことをいいます。
例えば、UNICODE, ASCIIコード, JISX0208, JISX0213などがあります。
コードポイントの表記としては、Unicode: U+0031(hex), JISX0208: 3区1点16のように表現されます。
文字符号化方式(CES)
文字集合(CCS)を符号化してコンピュータで扱えるようにするエンコード方式のことです(Character Encoding Scheme)。
文字集合(CCS)の一覧表によって「文字からコードポイント」を変換し、符号化方式(CES)によって「コードポイントからコンピュータ用の数値」に エンコーディングするイメージみたいです。
例えば、Shift-JIS, UTF-8, UTF-16があります。
文字コードはどの文字集合(CSS)に存在するかで異なり、そこで一意のコードポイントが決まります。
世界にはさまざまな文字集合(CCS)が存在し、それをコンピュータ用に変換する方式が符号化方式(CES)ということです。
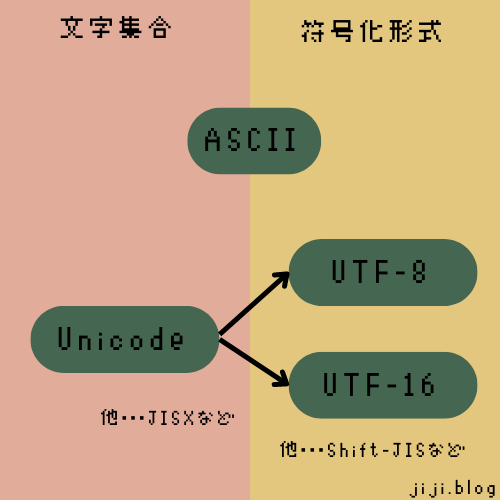
符号化文字集合(CCS)の例
ASCIIコード
American Standard Code for Information Interchangeの頭文字を取ってアスキーと呼びます。
元々アメリカが定義した集合なので、英語・数字・一部記号などの表となり、約92種類の文字が定義されています。
92種類の文字は、7bitで表現が可能となりますが、7は中途半端なので、8bitで表現されます。1ビット余りますが、予備ということで定義しているらしいです。
ASCIIコードでググると対応表が出てくるはずです。
Unicode
ASCIIが英語・数字・一部記号しか表現できなかったことに対し、Unicodeでは世界の文字が表現できる文字集合となります。絵文字も含まれているとか!
Unicodeの対応表についてもググると出てきます。2byteのバイト列で表現されているみたいですね。
Unicodeの未使用部分を活用して、表現する文字を拡張したのがサロゲートペアといいます。それは以降の章で解説します。
文字符号化方式(CES)の例
UTF-8
Unicodeを変換するのに使われ、1~4byteまでのバイト列を取る可変長の符号化方式です。
こちらのUTF-8項で詳しく解説されているのですが、UTF-8で変換されることで、Unicodeコードポイントの2byteのバイト列が3byteのバイト列になるということみたいです。
半角英数字1文字は1byte, 日本語1文字は3byteと一般的に言われてるようなので、文字によって可変になるようです。
ASCIIと互換があるってどういうこと?
調べていると、UTF-8はASCIIと互換があるらしいです。
でも、ちょっとまて・・・ASCIIは文字集合であって、UTF-8は文字符号化方式なので、互換性があるってどういうことなの?となりました。
調べてみると、ASCIIの文字符号化方式は存在しないみたいです、
コードポイントがそのままコンピュータ用の数値とイコールになるため、符号化方式は必要ないみたいです。
ASCIIで表現できる文字に関しては、UTF-8で変換してもASCIIのバイト列と一緒になるようにしてあるってことなのかなと解釈しました。
UTF-16
Unicodeを変換するのに使われ、2byteで表現される固定長の符号化方式です。
UTF-8は、可変長なので、プログラム上で操作するにはちょっと複雑なようです。なので、可変長のUTF-16が登場というわけらしいです。
さて、2byteということなので、2byte(2^16=65536)ですべての文字を表現できると思っていたみたいですが、どうやら難しかったようです。
しかし今から3byteに拡張してしまうと、2byteで実装しているプログラムの互換性が取れなくなってしまいます。
例えば、0x0041が0x000041となってしまうということですね。
これを解消して、さらにたくさんの文字を表現するために使用するのがサロゲートペアです。
サロゲートペアとは
1文字2byteは基本にしつつ、一部の文字に関しては1文字4byteとして定義する方法です。
Unicodeには未使用部分があり、0xD800~0xDBFF(1024通り)を「上位サロゲート」、0xDC00~0xDFFF(1024通り)を「下位サロゲート」と規定することにしました。
こうすることで、「上位サロゲート+下位サロゲート」の4バイトで文字を表現できるようになったのです。1024*1024=1048576となったので、これだけの文字を追加することができます。
その他
Base64
主にメールで使うSMTPプロトコルで使われる形式で、画像やテキストを変換するのに使われます。MIMEという規格が定義されて、base64が定義されたようです。
画像データをbase64変換ルールに従って変換し、base64の変換図を用いてバイト列に直せます。変換方法はこちらがわかりやすいです。
これは文字集合なのか、符号化方式なのかちょっとわからないです。そもそもどちらの領域にも入らないのかもしれません。
文字化けの原因
一度は経験があると思いますが、webサイトやテキストファイルを開いてみると、文字が意味不明のものに変わっている・・。
これは文字集合と符号化形式のペアが正しくない場合に起きます。直すためには、正しいペアを選択して読み込む必要がありそうですね。
まとめ
元々はCTFを解いていて、base64について調べていたところ、文字コードがそういえば曖昧な理解だったなあと思い出したのが、この記事を書いた経緯なのですが。
改めてわかりにくい・・。ただ、文字集合と文字符号化方式についての関係性やUTF-8やUnicodeがどっちに属するのかを理解できたのでよしとします。
にほんブログ村に参加しております!よろしければクリックお願いします 🙂
にほんブログ村


コメント